You can't govern what you can't see.
See every AI use case across your organisation. Govern them all from one place.
Where competitors send forms or scrape APIs and give a partial picture, we give the precise one — including the shadow AI no other vendor sees.
Built in Norway & the UK · Microsoft-stack-native · EMEA-sovereign by default
What you're looking at
One use case. Five things you need to know about it.
Every node on the live map is one of five colours. Here's a single example — an HR use case for CV screening — so you can read the rest at a glance.
Age / gender bias
CRITICAL
CV Screening
HR · medium risk
Priya Sharma
HR Director
CV Classifier
Classifier · finetuned
HireVue
Third-party SaaS
Every node on the map is one of these five colours. Click any node in the live dashboard to see the same five-piece breakdown for that use case.
The wedge
Desktop apps and browser extensions that see the actual prompt
Every other AI governance tool either asks employees to fill in a form, infers usage from network or SSO logs, or intercepts traffic at a proxy. Each method has a known bypass. Atlas AI observes — at the OS and browser level, on the employee's actual device, using the same accessibility APIs that power VoiceOver and UI Automation.
Other governance tools
- Ask — intake forms that depend on employees filling them in
- Infer — DNS, SSO logs, email metadata, OAuth grants
- Intercept — only sees traffic that crosses a SASE proxy
- Misses personal-account ChatGPT, desktop AI apps, mobile-data usage, and any tool that bypasses corporate SSO
Atlas AI
- Observe — on-device accessibility-API capture of the actual prompt the user types
- Sees the prompt content, the data pasted in, and the response it produced
- Bypass-proof — works even when employees use personal accounts or non-corporate networks
- EMEA-sovereign by default — processing happens on the device; sensitive prompt content never leaves the endpoint
Where we run · five surfaces, one register
macOS app
macOS Accessibility APIs
Claude Desktop, ChatGPT desktop, Cursor, Raycast AI, Notion AI, Perplexity, internal Mac apps
Windows app
UI Automation framework
Copilot for Windows, Edge Copilot, Office AI, Teams Copilot, Notion, Electron apps
Chrome extension
Manifest V3 content script
ChatGPT, Claude, Gemini, Copilot Web, Perplexity, internal LLM UIs
Safari extension
macOS Safari Web Extension
Same coverage in Safari — critical for Mac-heavy creative and exec users
Edge extension
Manifest V3 (shared codebase)
Microsoft 365 Copilot, Bing Chat, ChatGPT in Edge — the M365-native surfaces
“If your AI governance tool can't tell you what was pasted into ChatGPT yesterday, it's a registry — not a control tower.”
The Problem
AI is spreading faster than you can keep track
Sales writes pitches with AI. Finance forecasts with it. HR screens CVs with it. Most of it never got a security review and nothing's on a single list. Now the regulator is asking what AI you're running — and assuming you can answer.
No single inventory
AI tools are discovered ad hoc, by accident, or not at all.
No risk linkage
Even catalogued tools have no assessed risk, no severity, no mitigation status.
No ownership
When an AI system causes harm, no one knows who is accountable.
No compliance readiness
EU AI Act deadlines are live. Most organisations cannot produce evidence of controls on demand.
No early warning
Security teams learn about rogue AI deployments from incidents, not dashboards.
This isn't a future risk. It's today's exposure.
What it does
Six questions every AI governance programme has to answer
Atlas AI is built around the six questions a CISO or CIO needs an answer to — on demand, in front of an auditor, in the boardroom, in the next incident.
What AI are we running?
How do we find it all?
Who owns each use case?
What are the risks?
Are we compliant?
How healthy are our models?
Who it's for
Built for the people accountable for AI
Atlas AI speaks the language of every stakeholder in your AI governance programme — from the boardroom to the engineering team to the compliance auditor.
The CISO
You own AI risk but you don't control AI adoption. Atlas AI gives you the live map of what's running, the exposure, and whether mitigations are in place — without waiting for the next incident to find out.
The CIO
You're being asked for a single source of truth on enterprise AI — what's deployed, who owns it, what it costs, where the duplication is. Atlas AI turns sprawl into a structured portfolio you can govern.
The AI Governance Lead
You're standing up the programme. Atlas AI operationalises your policy — intake workflows, compliance coverage tracking, owner assignment, lifecycle status — in one command centre.
The Compliance Officer
You need evidence for the EU AI Act, NIST AI RMF, ISO 42001, and OWASP LLM Top 10. Atlas AI maps every use case to its framework obligations and surfaces coverage gaps before auditors do.
The AI Product Owner
You build and run AI features. Atlas AI gives you a structured intake flow, a clear list of risks to mitigate, and a compliance scorecard — so you can prove you've done the work.
The Enterprise Architect
Your EA tooling maps systems and capabilities. Atlas AI goes one layer deeper — into what AI is running inside those systems, who owns it, and whether it's governed. Complementary, not competitive.
Where we sit
Between the tools you already have
Atlas AI is the missing piece. Ardoq AI Lens draws the picture of what AI lives inside your business — but it can't see what your team is actually using. Microsoft Purview and Defender protect the data once you know what to protect — but they can't make the list. We do that bit. Then we feed both.
Board · Audit committee · Regulator
EA portfolio · enriches with capability + ownership
Ardoq AI Lens
AI as nodes in the business-capability + technology graph. Declared, EA-curated.
AI Control Tower · live discovery + framework registry
Atlas AI
Live inventory · risk score against EU AI Act, NIST AI RMF, ISO 42001, OWASP LLM Top 10 · desktop + browser-extension accessibility-API discovery. Observed, real-time.
Data-protection runtime · prompt/data-level controls
Microsoft Purview · Defender · Entra Agent ID
Purview DSPM for AI · Defender for Cloud Apps generative-AI catalog · Entra agent identity and registry.
Endpoints · Browsers · SaaS AI tools · Internal LLM apps · MCP agents
Ardoq AI Lens — what it does well
Maps AI to business capabilities, owners, and value. Inherits Ardoq's EA graph and Discover narratives.
What it doesn't do: live employee-side discovery, prompt-level visibility, OWASP/NIST scoring.
Microsoft Purview — what it does well
Classifies AI activity across M365 Copilot, ChatGPT Enterprise, Foundry. Enforces DLP at the data level.
What it doesn't do: business use-case framing, non-Microsoft browsers as first-class, macOS-native discovery.
Core capabilities
From discovery to audit-ready evidence
Six modules that share one register and one risk model. No data silos, no separate tools to wire together, no policy that lives only in a Confluence page.
Map
See your entire AI landscape at once
A live, interactive force-directed graph of every AI use case alongside its connected models, vendors, owners, and risks. Filter by department, risk severity, or compliance status. Click any node to open a full detail panel with risk cards tagged to OWASP, EU AI Act, and NIST. Unowned use cases are flagged in red, instantly.
Discover
Find AI before it finds you
Three discovery modes that work in parallel: AI agents conducting structured interviews with department leads (no manual surveys), employee self-registration via a low-friction conversational intake, and auto-detection through Okta integration that monitors SaaS access patterns and flags AI-adjacent tools.
Register
Structure what you know
Every discovered use case flows through a five-stage pipeline — Discovered → Assessed → Owned → Mitigated → Compliant — with counts, status, and filterable views. Capture description, data classification, models, vendors, owner, risk assessments, mitigations, and framework mappings as the source of truth.
Owners
Close the accountability gap
Track ownership at the use case level: who is accountable, what they own, whether they have completed their assessment. Overdue flags and notification triggers keep the programme moving. When something goes wrong, "we didn't know who owned it" is no longer a defensible answer.
Comply
Turn frameworks into evidence
Every registered use case is mapped to four major frameworks. Coverage shown as live stacked progress bars (covered / partial / gap), with priority remediations ranked by criticality and deadline. Use case-level scorecards accessible from the Map detail panel.
AI Governance
Your Atlas AI command centre
Aggregate risk scores, compliance posture per framework, incident tracking with severity and status, risk distribution visualised, and use case health indicators. Built for security teams managing AI risk at scale — generic SIEMs and GRCs were not built for this.
The full workflow
Compliance coverage
Four frameworks, one coverage view
Every registered use case is mapped to the four frameworks regulators and auditors will ask about. Coverage is shown live, gaps are prioritised by criticality and deadline.
EU AI Act
Risk classification (Unacceptable / High / Limited / Minimal), prohibited-practice screening, conformity assessment readiness, technical documentation tracking, human oversight evidence.
NIST AI RMF
Govern, Map, Measure, Manage. Organisational and technical controls across the full risk-management lifecycle.
OWASP LLM Top 10
Prompt injection, insecure output handling, training data poisoning, model DoS, supply chain, sensitive info disclosure, insecure plugins, excessive agency, overreliance, model theft.
ISO 42001
AI management system establishment, organisational context, risk and opportunity management, AI system impact assessment, continual improvement.
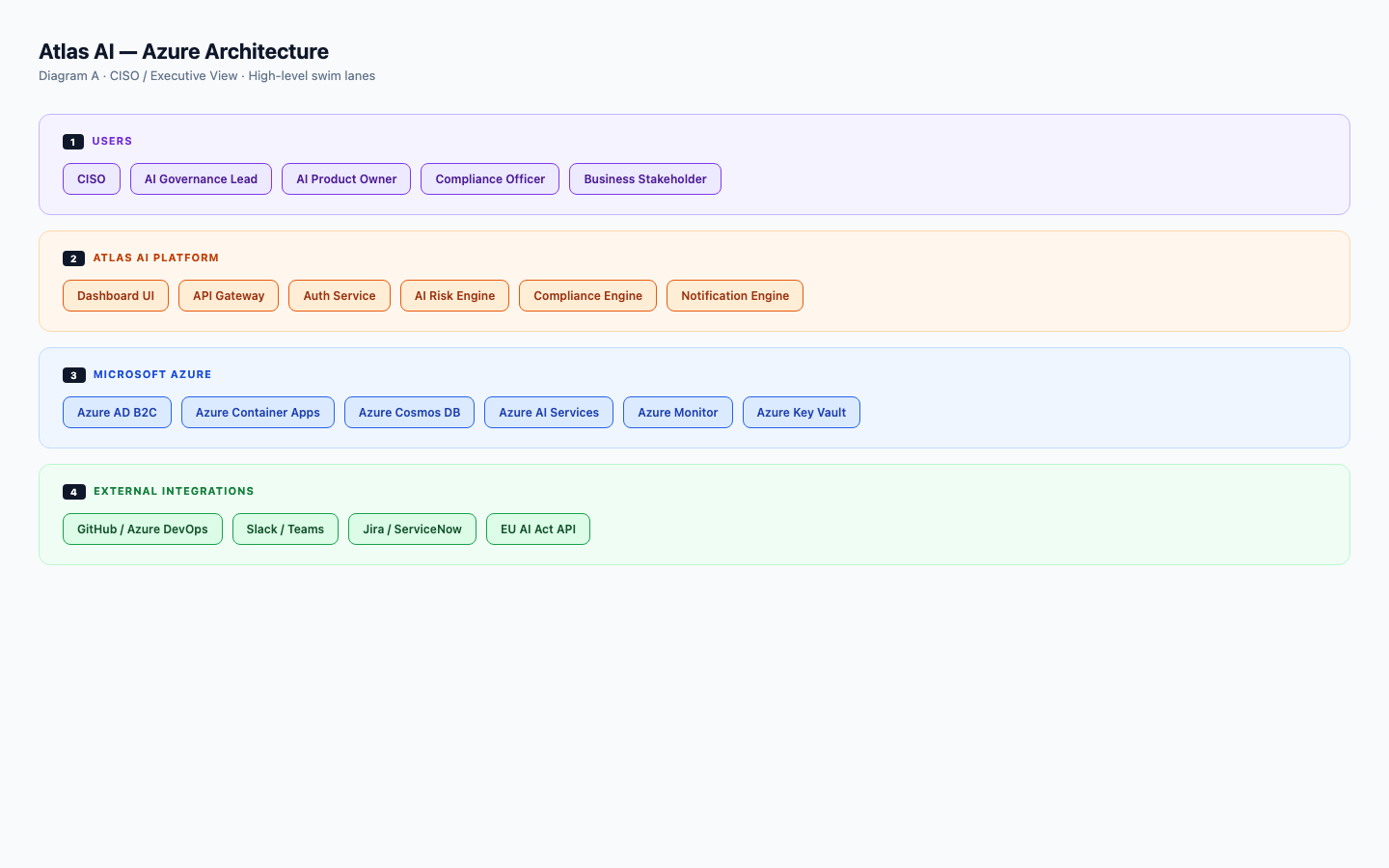
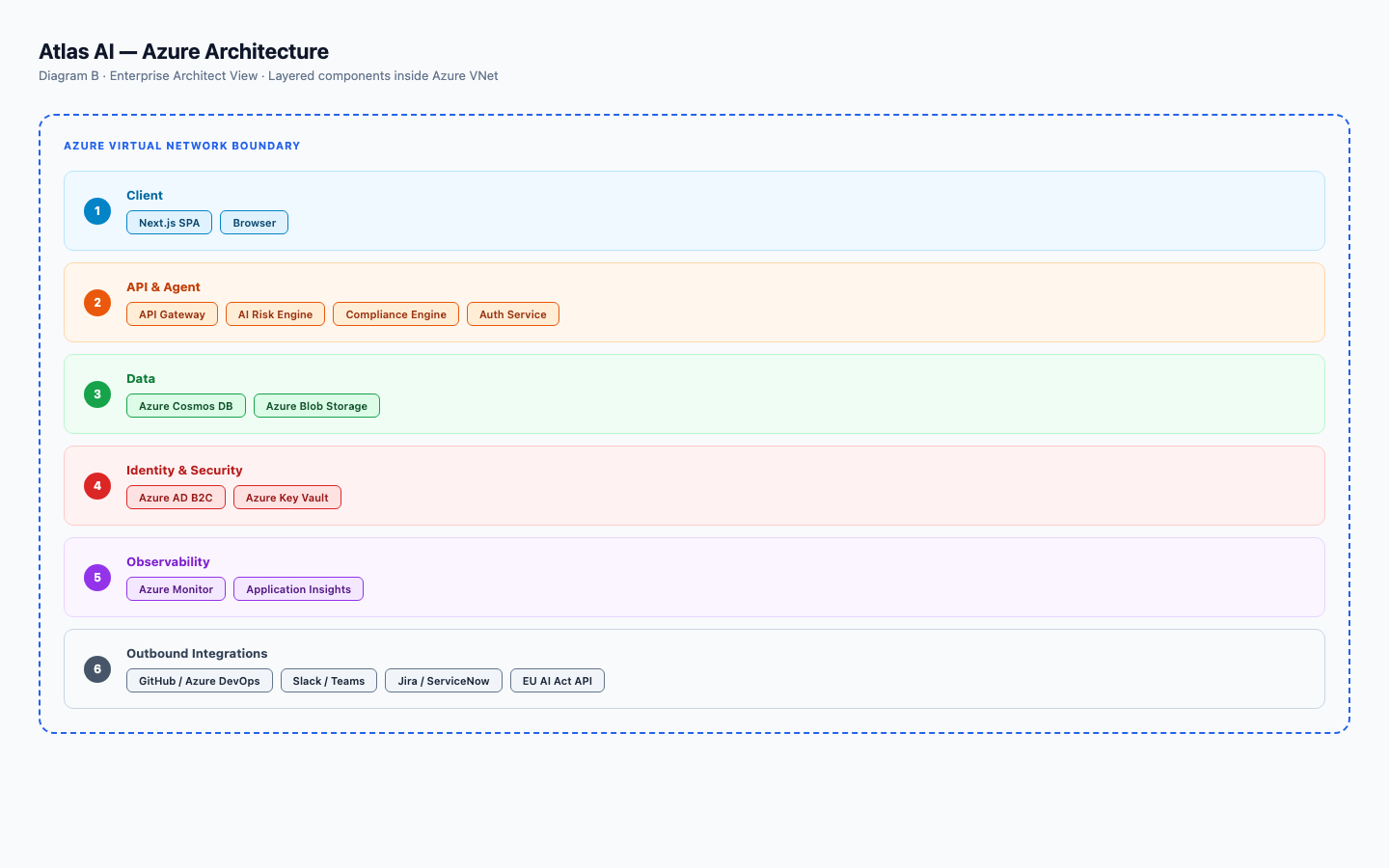
Architecture
Built on Microsoft Azure. Ready for big companies.
Sign-in via Azure AD B2C. Secrets locked in Azure Key Vault. Logs in Azure Monitor. Data stored encrypted across regions in Azure Cosmos DB. Everything runs inside a private network. The same setup your IT team already uses.
CISO / Executive view
Enterprise architect view
Azure AD B2C
Container Apps
Cosmos DB
Azure Monitor
Key Vault
Integrations
Connects to the tools your teams already use
Identity
- Okta
- Azure AD B2C
Development
- GitHub
- Azure DevOps
Communication
- Slack
- Microsoft Teams
Ticketing
- Jira
- ServiceNow
Regulatory
- EU AI Act API
SIEM (roadmap)
- Microsoft Sentinel
- Splunk
- Chronicle
How a pilot runs
Four weeks. ~5 hours of customer time. We do the rest.
A 4-week paid pilot is the standard sales motion. It produces a real AI use-case register, a risk heatmap, a 4-framework gap report, and an audit-ready evidence pack — for your organisation, not a demo dataset.
Day 0
Sign pilot SOW
4-week paid pilot, €5–8K. Pilot fee credits to year-1 if you convert within 30 days.
Day 1–3
Stand up your tenant
We provision your dedicated Atlas AI tenant. You connect Entra ID or Okta — that's it.
Day 4–7
Deploy desktop app + browser extensions
Desktop app rolled out to 50–100 pilot employees via MDM. AI agent interviews launch in Microsoft Teams in parallel.
Week 2
Discovery runs itself
AI use cases populate the Map. Risks classify automatically. Shadow AI surfaces — including personal-account ChatGPT, desktop apps, custom GPTs you didn't know existed.
Week 3
Owners validate
Business owners notified per use case. Each spends ~1 hour validating their assigned use cases and signing off on remediations. Critical risks routed to incident workflow.
Week 4
Governance readout
30-minute board-ready readout: AI use-case register · risk heatmap · 4-framework gap report (EU AI Act, NIST AI RMF, ISO 42001, OWASP LLM Top 10) · audit evidence pack.
Day 30
Decision
Convert to annual SaaS (€15K / €30K / €100K by employee band) or walk away. If you convert, the pilot fee credits against year-1.
What you get
A live AI register that didn't exist before
By Day 30 you have the inventory, the risk scoring, the owner assignments, and the audit-ready evidence pack. Not a deck. Not a Confluence page. A live system that keeps itself current.
All AI use cases discovered
Including the shadow AI no API connector or SSO log can see — personal-account ChatGPT, desktop apps, custom GPTs, MCP agents.
Owners identified per use case
Explicit accountability with sign-off status. "We didn't know who owned it" is no longer a defensible answer.
Risks classified across the board
Nine risk categories + EU AI Act risk tier. Scored against observed prompt content, not declared use cases.
Concrete remediation actions
Suggested AND initiated — not just flagged. Routed to your existing ITSM, Jira, ServiceNow, or Slack workflow.
Audit-ready evidence pack
Coverage report mapped to EU AI Act, NIST AI RMF, ISO 42001 and OWASP LLM Top 10. The pack you'd give an auditor on Monday.
Continuous discovery
Live, not quarterly. The view stays fresh as employees adopt new AI tools — including the ones IT hasn't approved yet.
Optional add-on
In-flow employee assistant — desktop and browser nudges that suggest better prompts, MCP-aware guidance, and policy-aligned alternatives at the point of use. Available as an upgrade on the annual plan.
Why us
Built by practitioners who've shipped this category before
Atlas AI is built by a Norwegian/UK team with 40+ years combined experience in secure, compliant Microsoft-based enterprise software. The product is shaped directly by what enterprise security and AI leaders say they need — not by a generic governance template.
40+ years building secure enterprise software
Combined experience delivering compliant, Microsoft-based enterprise systems. We've shipped this category of product before — we're not learning on your dime.
100+ CISO, CIO & Head of AI conversations
In the last 12 months alone. Every capability in Atlas AI maps to something a real enterprise security or AI leader said they needed.
Microsoft-stack-native
Out-of-the-box integration with Entra ID, Purview, Microsoft Teams, and Azure. We complement Purview / DLP — we don't replace them.
Backed by Microsoft and the Nordic ecosystem
Partner of Microsoft for Startups and member of Tek Norge. Backed by Antler, Innovation Norway, and StartupLab.
Founding team
Tage Ringstad
Co-founder & CEO
MSc Indøk, NTNU. Ex-management consultant and VC.
Jun Seki
Co-founder & CTO
4× CTO. 15+ years in security & privacy software, 15+ years leading B2B enterprise software.
Augmented by a senior team of developers, privacy, GRC, AI and security experts.
Headquarters
Oslo, Norway
EMEA HQ
London, United Kingdom
UK presence
Backers & partners
See your AI estate before your auditor does
A 30-minute walkthrough of Atlas AI with a real, populated dashboard. We'll show you the Map, the Comply view, and the discovery flows — and discuss how it would fit your environment.